
 | ÁREA: LOGICA Y ESTADISTICA | GRADO: 11° |
DOCENTE: ENAIDO MALDONADO POLO | CORREO: matematica. ceqa@gmail.com | |
FECHA: DEL 8 DE MAYO DEL 2024 | PERIODO: SEGUNDO | |
VALOR: SENTIDO DE PERTENENCIA | FRASE: "SOMOS CEQUEANISTAS FORMADOS EN VALOR, LLEVAMOS EN LA SANGRE RESPETO EDUCACION" |
FECHA: DEL 8 DE MAYO DEL 2024
GRADO: 11°
TEMA: RAZONAMIENTO INDUCTIVO
SUBTEMA: RAZONAMIENTO INDUCTIVO (CONTINUIDAD CLASE ANTERIOR)
LOGRO. Reconoce la lógica y las proposiciones para aplicarla en la vida cotidiana.
Razonamiento inductivo
¿Qué es un razonamiento inductivo?
Un razonamiento inductivo es un tipo de argumento cuya premisa identifica patrones de los que se extrae una conclusión general.
Entonces, ¿para qué sirve un argumento inductivo? Sirve para iniciar una nueva investigación científica, cuyo propósito es comprender las leyes que rigen la realidad. También sirve para hacer predicciones.
Los razonamientos inductivos, por lo tanto, se caracterizan porque aportan información, son ampliativos y falibles. Sus conclusiones son probables, pero no son válidas. Forman parte de los principales tipos de razonamiento, junto al deductivo y al abductivo.
Características de los razonamientos inductivos
Los argumentos o razonamientos inductivos tienen las siguientes características:
- Son ampliativos. Esto quiere decir que la conclusión aporta más información que la premisa.
- Son falibles. Significa que las conclusiones de un argumento inductivo no son definitivas.
- No son validables. Los argumentos inductivos no se pueden validar dado que sus conclusiones son probables, no definitivas.
- Aportan nueva información. Los argumentos inductivos son muy utilizados en la investigación científica, ya que aportan nuevo conocimiento que debe ser corroborado.
Estructura de un razonamiento inductivo
En general, todos los razonamientos o argumentos parten de una estructura formada por una premisa y una conclusión.
Se llama premisa a una información que se presenta como cierta y funciona como base de un argumento. En los argumentos inductivos, la premisa refiere casos específicos. Debe identificar un individuo, la clase a la que pertenece y la propiedad que se le atribuye.
La conclusión debe comenzar con el enunciado “probablemente” y, enseguida, debe formularse usando los elementos de la premisa. Veamos la estructura base:
| Premisa | El individuo A forma parte de la clase X y tiene la propiedad P. El individuo B forma parte de la clase X y tiene la propiedad P. El individuo C forma parte de la clase X y tiene la propiedad P. n... (así sucesivamente) |
|---|---|
| Conclusión | Probablemente, todos los individuos que forman parte de la clase X tienen la propiedad P. |
| Ejemplo | Los gatos son mamíferos, tienen pulmones y amamantan a sus crías. Los delfines son mamíferos, tienen pulmones y amamantan a sus crías. Los seres humanos son mamíferos, tienen pulmones y amamantan a sus crías. Probablemente, todos los mamíferos tienen pulmones y amamantan a sus crías. |
Dependiendo del caso, esta estructura puede simplificarse, pero en términos técnicos, se cumplen los mismos elementos. Dicha forma resumida sería: «Los gatos, los delfines y los seres humanos tienen pulmones y amamantan a sus crías. Probablemente, todos los mamíferos tienen pulmones y amamantan a sus crías».
ACTIVIDAD EN CASA:
REALIZA 10 EJEMPLOS DE INDUCCION
CLASIFICA LA PREMISA Y LA CONCLUSION.
ESTADISTICA
Una variable aleatoria continua puede tomar cualquier número real. Por ejemplo, las rentabilidades de las acciones, los resultados de un examen, el coeficiente de inteligencia IQ y los errores estándar son variables aleatorias continuas.
Una variable aleatoria discreta toma valores naturales. Por ejemplo, el número de estudiantes en una universidad.
Fórmula de la distribución normal
Dada una variable aleatoria X, decimos que la frecuencia de sus observaciones puede aproximarse satisfactoriamente a una distribución normal tal que:
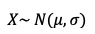
Donde los parámetros de la distribución son la media o valor central y la desviación típica:

En otras palabras, estamos diciendo que la frecuencia de una variable aleatoria X puede representarse mediante una distribución normal.
Representación
Función de densidad de probabilidad de una variable aleatoria que sigue una distribución normal.
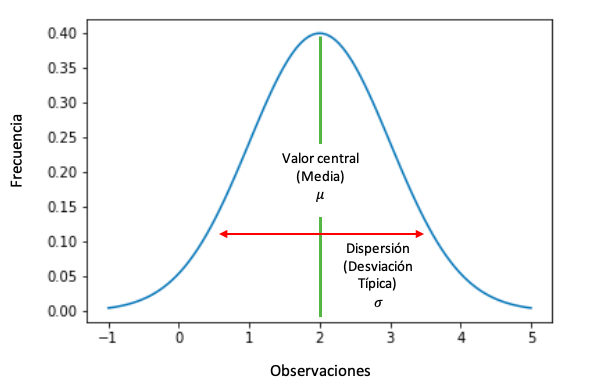
- Es una distribución simétrica. El valor de la media, la mediana y la moda coinciden. Matemáticamente,
Media = Mediana = Moda
- Distribución unimodal. Los valores que son más frecuentes o que tienen más probabilidad de aparecer están alrededor de la media. En otras palabras, cuando nos alejamos de la media, la probabilidad de aparición de los valores y su frecuencia descienden.
¿Qué necesitamos para representar una distribución normal?
- Una variable aleatoria.
- Calcular la media.
- Calcular la desviación típica.
- Decidir la función que queremos representar: función de densidad de probabilidad o función de distribución.
Ejemplo teórico
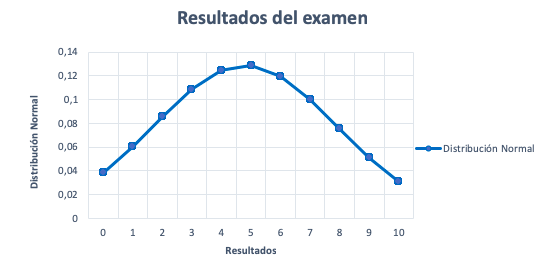
Suponemos que queremos saber si los resultados de un examen pueden aproximarse satisfactoriamente a una distribución normal.
Sabemos que en este examen participan 476 estudiantes y que los resultados podrán oscilar entre 0 y 10. Calculamos la media y la desviación típica a partir de las observaciones (resultados del examen).
Entonces, definimos la variable aleatoria X como los resultados del examen que depende de cada resultado individual. Matemáticamente,
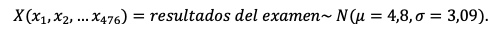
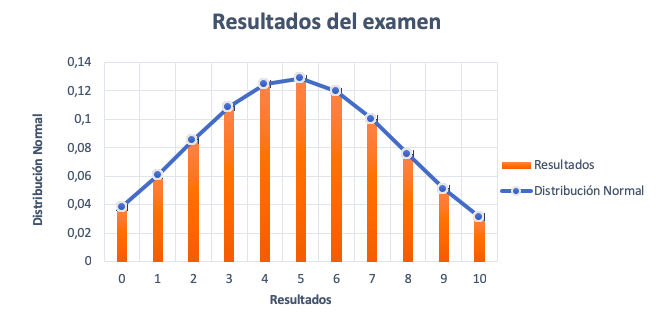
El resultado de cada estudiante se anota en una tabla. De esta forma, obtendremos una visión global de los resultados y de su frecuencia.
| Resultados | Frecuencia |
| 0 | 20 |
| 1 | 31 |
| 2 | 44 |
| 3 | 56 |
| 4 | 64 |
| 5 | 66 |
| 6 | 62 |
| 7 | 51 |
| 8 | 39 |
| 9 | 26 |
| 10 | 16 |
| TOTAL | 475 |
Una vez hecha la tabla, representamos los resultados del examen y las frecuencias. Si el gráfico se parece a la imagen anterior y cumple con las propiedades, entonces, la variable resultados del examen puede aproximarse satisfactoriamente a una distribución normal de media 4,86 y desviación típica de 2,56.
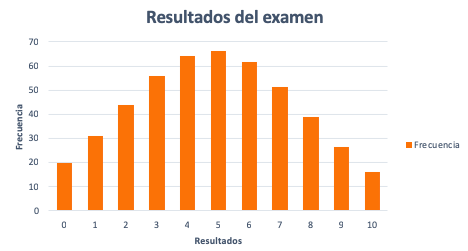
¿Los resultados del examen pueden aproximarse a una distribución normal?
Razones para considerar que la variable resultados del examen sigue una distribución normal:
- Distribución simétrica. Es decir, existe el mismo número de observaciones tanto a la derecha como a la izquierda del valor central. También, que la media, la mediana y la moda tienen el mismo valor.
Media = Mediana = Moda = 5
- Las observaciones con más frecuencia o probabilidad están alrededor del valor central. En otras palabras, las observaciones con menos frecuencia o probabilidad se encuentran lejos del valor central.
No hay comentarios.:
Publicar un comentario